Internet user search query categorization
Task: The task is to categorize internet queries into 67 predefined categories. For example, a search query "Saturn" might mean Saturn car to some people and Saturn the planet to the others. You should tag each query with up to 5 categories from the total 67 categories. Only a tiny set of labeled queries for showing semantics of categories is available. So, it will be considered as a non-straightforward learning problem. Queries are very short and the meaning and intention of search queries is subjective.
Data:
1) There is a sample file containing 111 queries and the manual categorization information. Each line starts with one query followed by its top 5 categories labeled by human experts, separated by tab. There may be fewer than 5 categories for some of the queries. It provides at least one sample query per category.
Download from here:CategorizedQuerySample.txt
To give an example, the first line in CategorizedQuerySample.txt looks like this:
"1967 shelby mustang Living\Car & Garage Sports\Auto Racing Living\Gifts & Collectables Shopping\Buying Guides & Researching Information\Companies & Industries"
Where "1967 shelby mustang " is the query and "Living\Car & Garage", "Sports\Auto Racing", "Living\Gifts & Collectables", "Shopping\Buying Guides & Researching", "Information\Companies & Industries"
are the category labels for this query. Elements in each line are separated by tab "\t".
2) The 67 predefined categories, where each line contains one category name is here: Categories.txt
Categories examples:
Entertainment\Celebrities, Computers\Software, Online Community\Homepages, Entertainment\Movies, Living\Car & Garage, Shopping\Stores & Products, Information\Education, Living\Career & Jobs, Sports\Basketball, Information\Science & Tech., Living\Fashion & Apparel, Sports\Outdoor Recreation
3) The 800 queries with labels from the three human labelers for evaluation are available to download:Labeled800Queries.zip
The collection of human editors is assumed to have the most complete knowledge about internet as compared with any individual end user.
Evaluation
You may combine the sample query data and the 800 queries data into one training data and use apply cross-validation on it to test your predictor. The prediction results are evaluated by the following three measures: precision, recall, and F-measure.
The evaluation will run on the held back queries and rank your results by how closely they match to the results from human editors. Here are the set of measures to evaluate results:
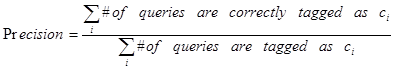
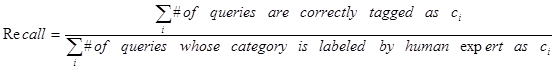
![]()